Abstract
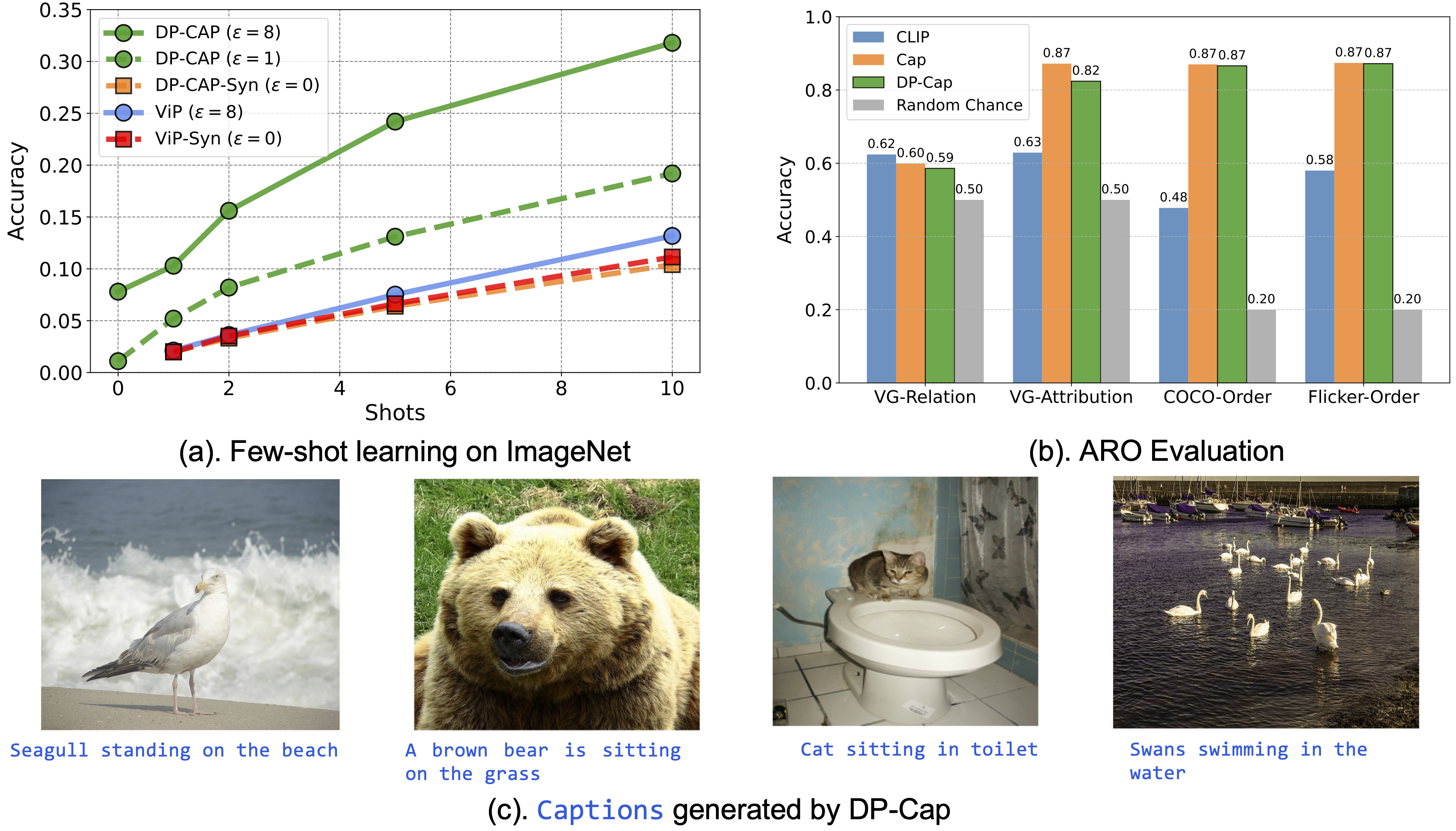
Differentially private (DP) machine learning is considered the gold-standard solution for training a model from sensitive data while still preserving privacy. However, a major barrier to achieving this ideal is its sub-optimal privacy-accuracy trade-off, which is particularly visible in DP representation learning. Specifically, it has been shown that under modest privacy budgets, most models learn representations that are not significantly better than hand-crafted features. In this work, we show that effective DP representation learning can be done via image captioning and scaling up to internet-scale multimodal datasets. Through a series of engineering tricks, we successfully train a DP image captioner (DP-Cap) on a 233M subset of LAION-2B from scratch using a reasonable amount of computation, and obtaining unprecedented high-quality image features that can be used in a variety of downstream vision and vision-language tasks. For example, under a privacy budget of \(\varepsilon=8\), a linear classifier trained on top of learned DP-Cap features attains \(65.8\%\) accuracy on ImageNet-1K, considerably improving the previous SOTA of \(56.5\%\). Our work challenges the prevailing sentiment that high-utility DP representation learning cannot be achieved by training from scratch.
Twitter Thread
Check our twitter thread!
"Differentially Private Representation Learning via Image Captioning". We've trained a DP image captioner on 200M+ image-text pairs, with SOTA DP image representation and better than non private MAE on certain taskshttps://t.co/BQtU0mtYXc@AIatMeta @berkeley_ai @Polytechnique pic.twitter.com/hfaXZievwp
— Tom Sander (@RednasTom) March 11, 2024