Abstract
Context
- Differential Privacy (DP) has become the gold standard to ensure that a machine learning model does not memorize its training data.
- DP-SGD is popular for training DNNs with (ε, δ)-DP guarantees by adding noise to clipped gradients. We explore how the noise can increase SGD’s implicit bias (small batch better than large).
- Why? Our ICML “TAN” (https://arxiv.org/abs/2210.03403) paper highlighted a DP-SGD bottleneck: it needs large batches for good privacy guarantees, but this can harm utility. Indeed, performance can decrease with batch size at fixed effective noise \(\sigma/B\) and fixed number of training steps.
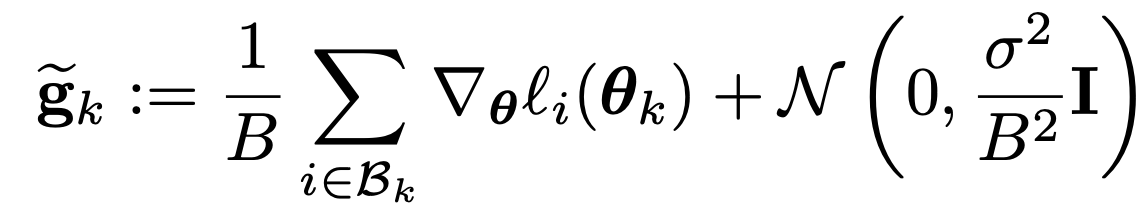
How?
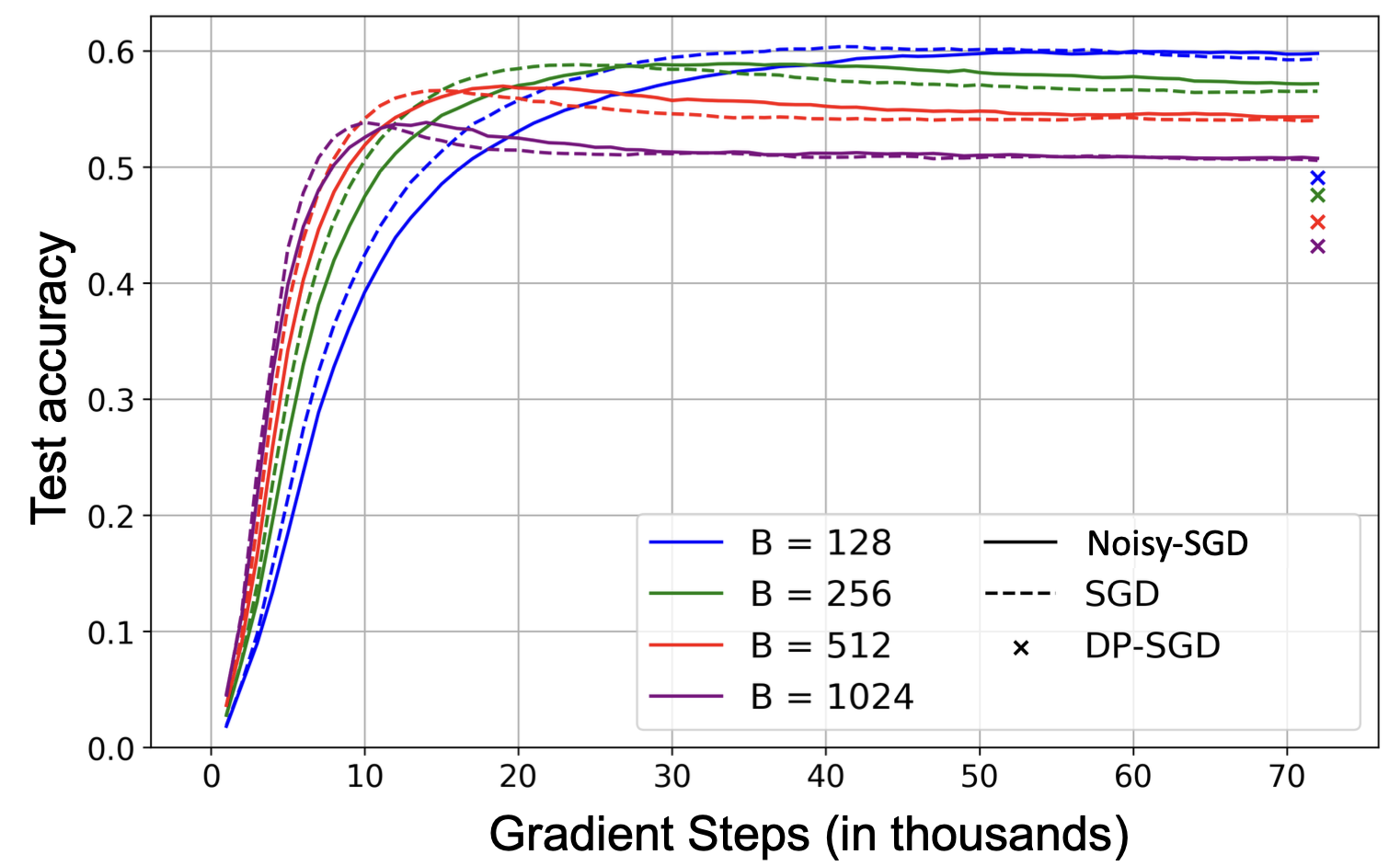
- For SGD, the noise structure inherent to stochasticity is known to cause the same implicit bias. Here we observe that Noisy-SGD (DP-SGD w/o clipping = SGD + gaussian) has a similar bias, even with (Big!) isotropic Gaussian noise. On ImageNet with a NF-ResNet, σ/B fixed:
- We thus study the solution of continuous versions of Noisy-SGD for Linear Least Square and Diagonal Linear Network (DLN). DLN is a non-convex toy NN that has properties similar to DNNs. We derive proofs that the implicit bias can indeed be amplified by the additional noise.
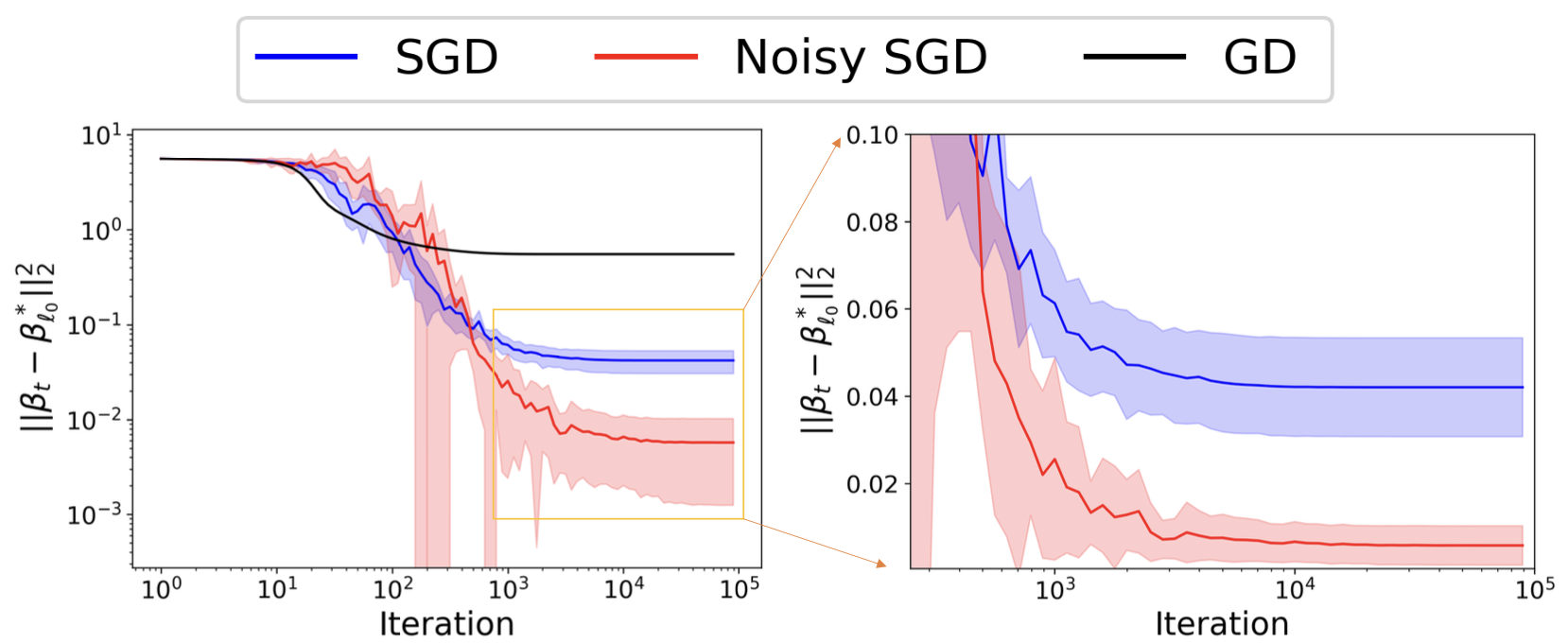
- e.g, for DLN, same setup as (Pesme et al., 2021), we look at a sparse linear regression. Our addition of Gaussian noise disrupts a crucial KKT condition, necessitating a mathematical alternative. We show that Noisy-SGD leads to a solution closer to the sparse ground truth than SGD.
- Disclaimer: Noisy-SGD is used as a DP-SGD substitute but differs from both a privacy and optimization perspective to the DP algorithm due to (1) vanishing noise and (2) non-clipped individual gradients. It is a first approx: see the paper discussion section.
- Future work could leverage methods developed to improve large-batch training in non-private settings to enhance DP-SGD performance.